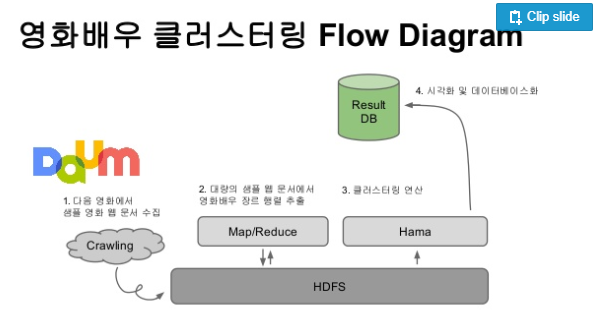
내가 보려고 만든 개념들
Hadoop
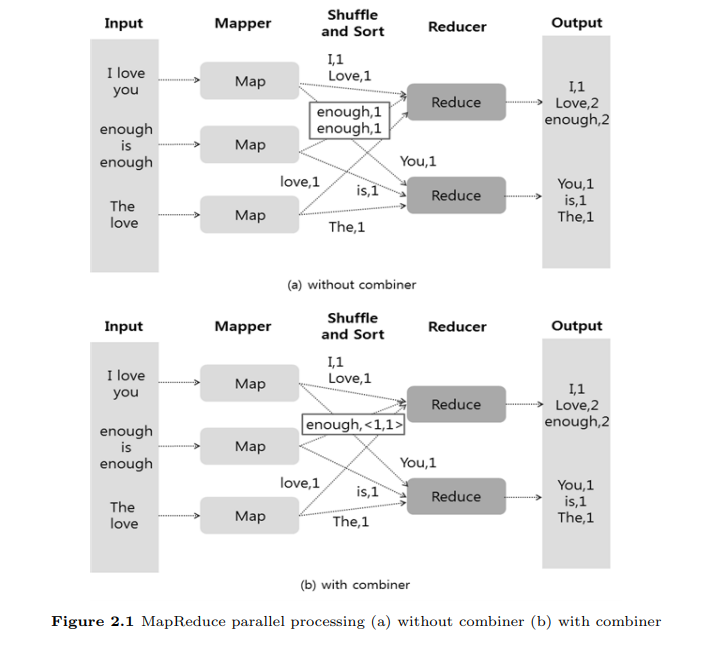
Input 은 입력데이터고 Mapper 와 Reducer 는 각각 Map 함수와 Reduce 함수의 기능을 수행하는 과정이고 Suffle and Sort 는 Mapper 로 부터 같은 키를 갖는 값들로 분류한 후 여러 Reducer 작업을 위해 파티션 되어 이동하는 과정을 말한다. 그리고 Output 은 출력데이터를 나타낸다.
MapReduce 의 동작과정에서 컴바이너를 사용하면 Mapper 과정에서 각 노드마다 계산된 결과를 키를 기준으로 집계하여 Reducer 로 전달됨으로서 Reducer 의 입력 데이터의 양을 줄여준다.
CRM 기반 고객 세분화 vs 고객 군집화
고객 세분화 : 유사성을 기반으로 고객들을 여러 그룹에 각기 수동으로 배치하는 것
대표적으로 인구통계학적(연령,성별,사는 곳,소득 등) 분류 과 고객 등급에 따라 고객을 분류하는 방법을 고객 세분화 고객 세분화의 경우에는 마케터가 설정한 기준에 따라 분류하는 것 이기 때문에 비 통계적인 방법이라고 할 수 있다.
고객 군집화 : 고객을 그룹으로 묶을 수 있도록 그들의 유사성들을 찾아내는 자동화된 통계적으로 엄격한 프로세스를 말한다.
타깃으로 살믕 사람을 사전에 알고 있는 것이 아니라 누구를 타깃으로 삼을 것인지를 발견하는 것으로 고객의 여러 요소를 사용하여 고객기반 속에 존재하는 세그먼트들을 자동으로 발견한다. 즉 자동으로 분류하고 각 레이블을 달아준다는 의미 인 것 같다.
군집화에 대해서 https://bcloved.github.io/Kmeans-Clustering-using-R/ 여기서 더 자세하게 설명해 놨다.