K-means 클러스터링(K-means clustering)
우리가 흔히 알고 있는 기계학습(Machine Learing)은 신경망에서부터 시작되었다.
기계학습(Machine learning)
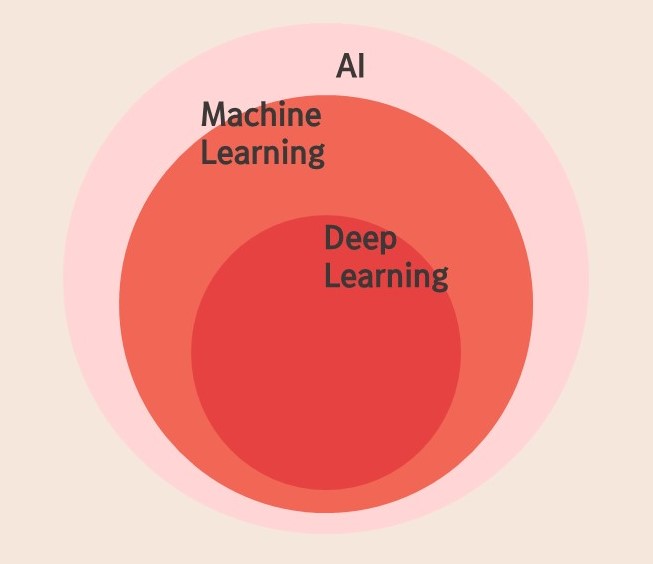
기계학습을 다이어그램으로 나타내자면 인공지능에 포함되며 이 기계학습은 딥러닝을 포함하고 있다.
기계학습(Machine learning) 의 분류
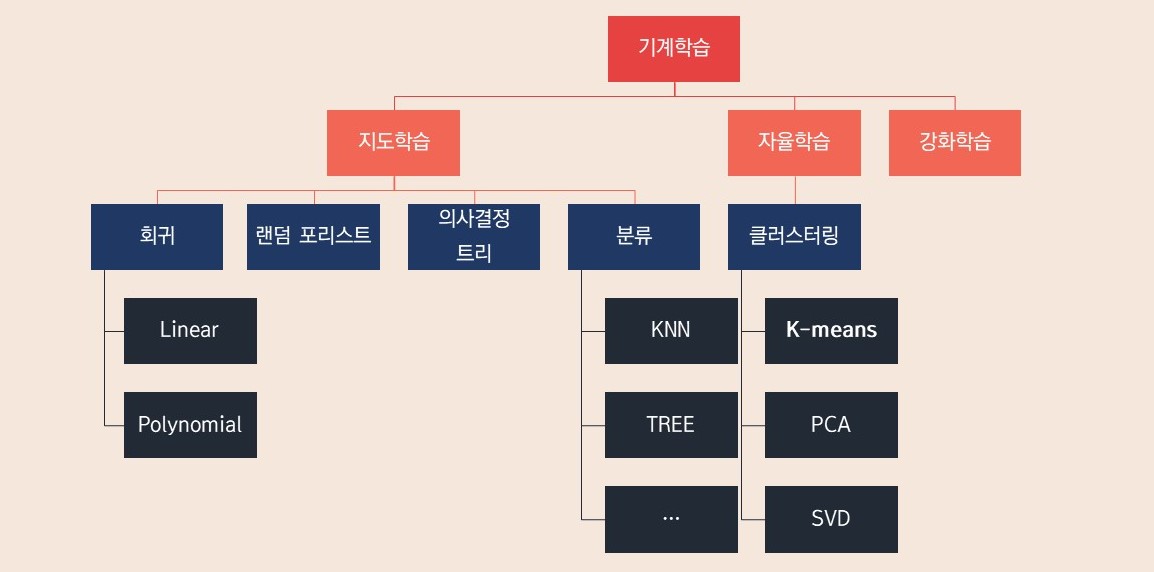
기계학습은 크게 지도학습(Supervised learning) , 자율학습(Unsupervised learning), 강화학습(Reinforment learning)으로 분류된다.
지도학습(Supervised learning) : (레이블이) 정해진 데이터를 가지고 학습을 진행하며 이를 Training Set 이라고도 부른다. 주어진 예제와 정답(레이블)을 제공받으며 입력을 출력에 매핑한다. 비지도학습(Unsupervised learning / 자율학습) : un-labeled data(레이블이 달려있지 않은 데이터) 와 정답이 주어지지 않지만 입력을 스스로 분류한다. 강화학습(Reinforment learning) : 처음에 학습 데이터가 주어지지 않으며 보상이나 처벌 형태로 피드백이 주어지면 피드백에 의하여 학습 데이터가 주어진다. 우리가 잘 알고 있는 알파고 같은 경우도 강화학습을 통해 학습시켰다고 알고 있다.
K-means 클러스터링
여기서 내가 설명할 K-means 같은 경우는 비지도학습(자율학습) 중 대표적인 학습이 클러스터링(군집화,clustering) 이며 이 클러스터링은 데이터간 거리를 계산하여 몇 개의 군집을 나누는 방법을 의미한다. 또한 K-means 클러스터링이 가장 고전적인 클러스터링 방법이다.
K-means 클러스터링은 입력데이터가 주어지면 k 개의 클러스터로 묶는 것을 의미한다.
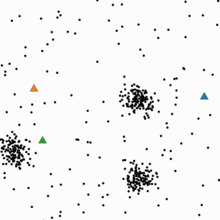
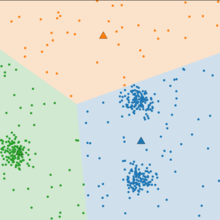
K-means 클러스터링은 유사한 대상끼리 그룹핑 하기 위해서 대상 간의 유사도, 거리를 측정하여 레이블이 달려 있지 않은 입력 데이터에 레이블을 달아주는 역할을 수행한다.
K-means 클러스터링 알고리즘
- 분석자가 설정한 K 개의 군집 중심점을 랜덤하게 설정한다.
- 관측치를 가장 가까운 군집 중심에 할당한 후 군집 중심을 새로 계산한다.
- 기존의 중심과 새로 계산된 군집 중심이 같아질 때 까지 반복한다.
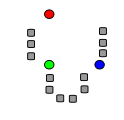
1) 초기에는 k ( 이 그림에서 k = 3 ) 평균값은 데이터 오브젝트 중에서 무작위로 뽑는다. (색칠된 동그라미가 무작위로 뽑힌 평균값)
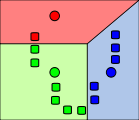
2) 각 데이터의 오브젝트들은 가장 가까이 있는 평균값 (점)을 기준으로 묶인다.
즉 빨간색 데이터 오브젝트는 빨간색 평균값과 더 가까운 거리에 있기 때문에 빨간색으로 라벨링 된 거고, 초록색 데이터는 초록색 평균값과 더 가까운 거리에 있기 때문에 초록색으로 라벨링 된 것이다.

3) 이 3개의 클러스터의 중심점을 기준으로 평균값이 다시 한 번 바뀐다.
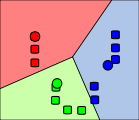
4) 이는 수렴될 때 까지 2,3 번 과정을 반복한다.
[출처] wikipedia k-means Algorithm
이 데이터들은 비정형 데이터들로 구분이 되어져 있지 않다. 그렇기 때문에 레이블을 달아줘야 한다.