[Project]수집한 데이터로 K-means Clustering 진행시키기
데이터수집 (https://bcloved.github.io/%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%88%98%EC%A7%91/) 에서 데이터를 어디서 모으는지에 대한 걸 보여줬다. 내가 본격적으로 데이터를 얻을 수 있었던 사이트는 kaggle https://www.kaggle.com 이라는 사이트였고, 거기서 사용자의 연평균 소득과 나이, 성별에 대한 데이터를 얻을 수 있었다. 이 데이터를 k-means algorithm 을 통해 군집화 시켜보려고 한다.
사용한 언어는 python을 사용했고 사용한 IDE 는 Jupyter Notebook 을 사용했다.
코드해석 && 결과
1. import library
library import 해오는 부분으로 여기서 내가 생소했던 라이브러리만 설명하겠다.
-
matplotlib.pyplot : 이건 kmeans 클러스터링 예제를 풀었던 곳에서도 사용했던 라이브러리인데 료를 차트(chart)나 플롯(plot)으로 시각화(visulaization)하는 패키지이다.
-
pandas: numpy행렬과 같이 쉼표를 사용한 (행 인덱스, 열 인덱스) 형식의 2차원 인덱싱을 지원하기 위해 다음과 같은 특별한 인덱서(indexer) 속성도 제공
2. dataset read

ds(dataset) 라는 변수에 pandas 를 이용하여 csv 파일을 데이터프레임으로 변환한다. 이때 파일 경로를 적어주면 되는데, 파일 경로는 \ 이거 아니다 / 이걸로 해줘야함. 귀찮음이 커서 그냥 경로 복붙했는데 오류나서 진짜 당황했다. 복붙하면 경로 ‘\ ‘ 이걸로 나옴
x = ds.iloc[:,[3,4]].values
이 문장의 의미를 먼저 말하자면, 3,4 번째 인덱스(실제로는 4,5 번째 열) 열 데이터의 values 들을 x 에 저장하라는 의미다.

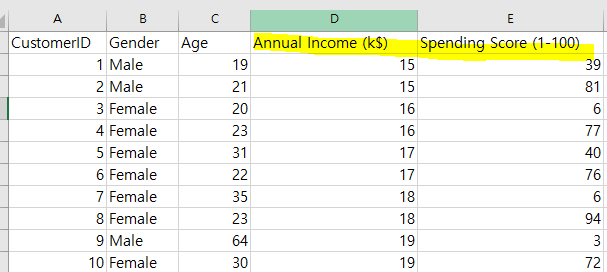 [실제 데이터파일]
[실제 데이터파일]
print를 찍어보니 데이터셋의 3,4번 째 열 데이터들이 저장된 걸 볼 수 있었다.
파일의 데이터를 행단위로 가져와야 하는데 판다스 라이브러리가 제공하는 함수가 그런 역할을 함.
총 두가지가 있는데 하나는 loc 또 다른 하나는 iloc 이 있음
| 속성 | 설명 | 사전적 설명 |
|---|---|---|
| loc | 인덱스 기준으로 행 데이터 읽기 | 라벨값 기반의 2차원 인덱싱 |
| iloc | 행 번호를 기준으로 행 데이터 읽기 | 순서를 나타내는 정수 기반의 2차원 인덱싱 |
여기서 사용한 함수는 iloc. 즉, 행 번호를 기준으로 데이터를 읽는 것이다.
둘의 차이가 뭘까 ? 인덱스는 사용자가 설정하기 나름이다. 한마디로 문자열로 설정할 수 도 있고, 숫자도 중구난방으로 설정할 수 있는데 인덱스 번호가 작은 것부터 읽는 것을 의미한다.
그에 비해 행 번호는 순서대로 1,2,3,4 읽는 것을 의미한다. 저기서 2번째 행이 삭제되더라도 행번호는 1,2,3 이 된다.
loc로 행 데이터 추출하기
데이터프레임변수.loc[인덱스]
여기서는 데이터프레임을 저장한 변수가 ‘ds’ 이기 때문에 ds.loc[인덱스]라고 해줘야한다.
ds.loc[0] : 0번째 인덱스 데이터를 가져오기 ! 인덱스 넘으면 오류 남
loc로 여러개의 인덱스에 해당하는 행 데이터 추출하기
데이터프레임변수.loc[[ 인덱스1,인덱스2,인덱스3 ]]
ds.loc[[0,1,2]] : 0,1,2 인덱스의 데이터를 한꺼번에 가져올 때 ! 리스트에 인덱스를 담아 loc 속성에 전달하면 된다.
iloc 속성으로 행 데이터 읽어오기
데이터프레임변수.iloc[행번호]
iloc를 통해 마지막 행 데이터 가져오기
데이터프레임변수.iloc[-1]
iloc를 통해 여러개의 행 데이터 가져오기
데이터프레임변수.iloc[[ 1행 , 2행 , -1 ]]
1행과 2행 그리고 마지막행을 가져오는 방법
iloc과 loc을 이용해 열 데이터 가져오기
데이터프레임변수.loc[:, [‘가져오고 싶은 열]]
> <b><span style="color:rgb(159, 125, 255)"> 데이터프레임변수.iloc[:, [열 인덱스 번호]]</span></b>
ds.loc[:,[‘gender’]]: gender 이라는 열의 데이터를 가져오라는 명령어 입니다.
ds.loc[:.[1,2,3]] : 1,2,3 번째 열의 데이터를 가져오라는 명령어
ds:iloc[:.:3] : 모든 행에 대하여 3번 열 데이터 전까지 모두 가져오라는 명령어
loc,iloc 응용
ds.loc[[1,4],[‘gender’]]
1,4 인덱스에 해당하는 행에서 gender 열만 가져오기
단 , iloc 의 경우에는 행과 열 인덱스에 정수리스트를 전달해줘야한다. (열 이름을 넣으면 error)
ds.iloc[[1,4],[0,1]]
1,4 번 행에서 0,1 인덱스 열의 데이터를 가져오기
3. elbow method 를 사용하여 최적의 클러스터 수 찾기
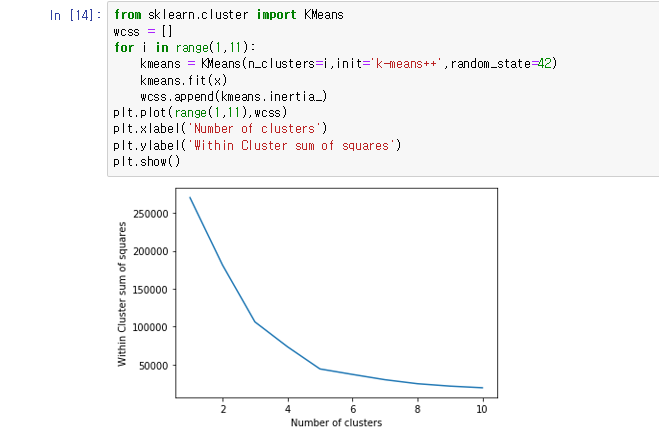
여기서는 Elbow Method 를 사용하여 k 의 수를 정했다. 거기에 대해 알고 싶은 사람들은 아래의 글을 참고하면 좋겠당
-
k의 수를 정하는 방법
- Elbow Method
- 클러스트의 수를 순차적으로 늘려가면서 결과 모니터링
- Within group 그래프에서 기울기가 완만해지는 곳을 Elbow Point라 하며 이때의 K가 적정값이라 판단
- K 갯수에 따라 cost function J를 그려보았을 때, 특정 K 이후 cost가 거의 변하지 않는 elbow point 가 있다면 그 K를 선택하는 것이 합리적일 것이다.
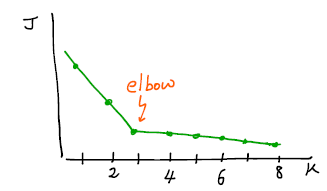
그러나 만약 다음과 같이 J 변화가 대체로 부드럽다면, elbow라고 부를만한 지점이 없다. 이 경우, elbow method로 K를 정하는 데에는 무리가 있다.
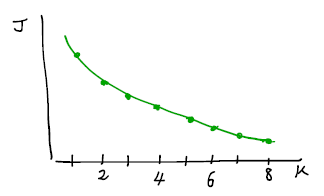
K-means를 이후 다른 application에 적용하기 위해 사용하는 경우라면, 해당하는 목적을 잘 만족하는지 평가하는 metric을 통해 K를 결정할 수 있다.
예를 들어 t-shirt 사이즈를 결정하는 경우, 예상되는 이익이 극대화되는 사이즈 종류 수를 선택하면 된다.
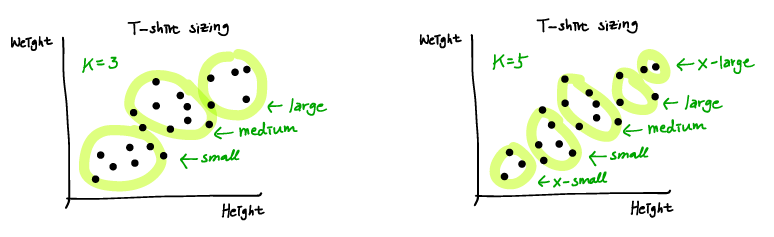 [출처 : https://wikidocs.net/4694]
[출처 : https://wikidocs.net/4694]
- Elbow Method
from sklearn.cluster import KMeans
scikit-learn 의 cluster 서브패키지는 K-MEANS Clustering 를 위한 KMeans 클래스를 제공한다. 이는 다음과 같은 인수를 받을 수 있다.
- n_clusters : 군집의 갯수
- init : 초기화 방법으로 “random” 이면 무작위 , “ k-means ++” 이면 k-means++ 방법 . 또는 각 데이터의 군집 라벨
- n_init : 초기 중심위치 시도 횟수, 디폴트는 10이고 10개의 무작위 중심위치 목록 중 가장 좋은 값을 선택한다.
- max_iter : 최대 반복 횟수
- random_state : 시드값
for i in range(1,11):
kmeans = KMeans(n_clusters=i,init=’k-means++’,random_state=42)
kmeans.fit(x)
wcss.append(kmeans.inertia_)
군집의 개수를 비교하기 위해 군집의 갯수가 1개 일때부터 11일 때까지 반복문을 돌려준다. 초기화 방법으로는 k-means ++ 를 사용한다. (k-means++ 에 대해 알고 싶은 분들은 https://bcloved.github.io/Project/ 게시물 참고해주세용)
그리고 fit 함수는 학습을 진행하는 함수다. kmeans 알고리즘으로 x에 저장된 데이터를 학습을 진행하는 것이다.
Inertia value는 군집화가된 후에, 각 중심점에서 군집의 데이타간의 거리를 합산한것이으로 군집의 응집도를 나타내는 값이다.
이 값이 작을 수록 응집도가 높게 군집화가 잘되었다고 평가할 수 있다. 이 inertia value는 KMeans 모델이 학습된 후에, model.inertia_ 값으로 뽑아 볼 수 있다. 한마디로 이 값들을 리스트를 담는 변수인 wcss 에 할당한다. (다시 한 번 말하지만 무엇이 가장 최적의 k 인지 알기 위해서 하는 것이다.)
plt.plot(range(1,11),wcss)
plt.xlabel(‘Number of clusters’)
plt.ylabel(‘Within Cluster sum of squares’)
plt.show()
시각화 하기 위한 라이브러리 matplotlib.pyplot 의 plt 를 사용해 inertia 값이 저장된 변수인 wcss 의 데이터들을 그래프로 나타낸다.
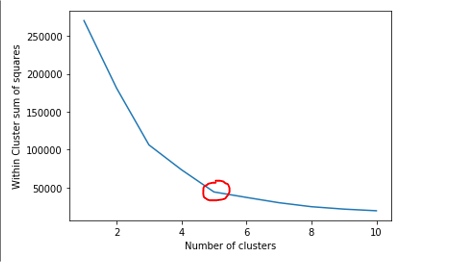
그래프를 보면 Cluster의 수(x축)값이 5에서부터 그래프가 완만해지는 것을 볼 수 있다. 그러므로 n_clusters (군집의 갯수) 의 값은 5가 적합하다는 것을 알 수 있다.
4. KMeans 학습하기

kmeans = KMeans(n_clusters=5,init=’k-means++’,random_state=42)
y_kmeans = kmeans.fit_predict(x)
n_clusters (군집의 갯수) 를 5로 설정하고, 초기화 방법으로 k-means ++ 그리고 시드 값은 42로 설정한 뒤 k-means 를 학습한 후 결과를 y_kmeans 변수에 저장한다.
5. 시각화
산포그래프(scatter plot)는 마커사이즈와 컬러를 이용하여 만든 플롯이다. 더 알고 싶은 사람들은 아래 내용을 참고.
작성형식
path = scatter(x,y,s=None,c=None)
x,y: x축과 y축을 numpy 배열같이 이터레이블한 자료형을 입력받는다. s
- 선택적으로 입력하면 되는데 마커의 크기를 설정한다.
- 마커의 크기를 바꿀 필요가 있을 때 입력하면 된다.
- 스칼라로 입력할 경우 마커의 크기는 고정이다
- x,y 와 같은 요소수를 가지는 이터레이블한 자료형을 입력할 경우 마커마다 다른 크기를 설정할 수 있다. c
- 역시 선택적으로 입력하면 되는데 마커의 색상을 설정한다.
- plot 에서 선과 동일한 코들르 입력하는 것이 가능하다.
- s와 마찬가지로 x,y 같은 요소수를 가지는 이터레이블한 자료형을 입력할 경우 각 마커마다 다른 색상을 설정할 수 있다.

scatter() 의 함수의 전체 매개변수를 나타낸다. 하지만 여기서는 위에서 설명한 x,y,s,c, 매개변수만 사용했다.
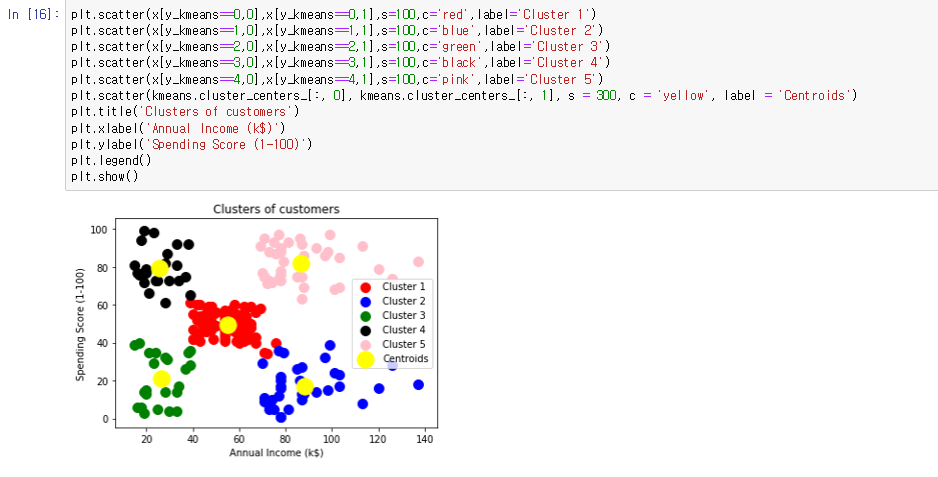
plt.scatter(x[y_kmeans==0,0],x[y_kmeans==0,1],s=100,c=’red’,label=’Cluster 1’)
 y_kmeans 가 0으로 군집화 된 데이터 값들(x)을 마커 크기 100 빨간색 점으로 Cluster1 이라고 분류한다.
y_kmeans 가 0으로 군집화 된 데이터 값들(x)을 마커 크기 100 빨간색 점으로 Cluster1 이라고 분류한다.
다른 것 역시 같은 값 (1,2,3,4) 로 군집화 된 데이터 값들을 군집화 하여 각 다른 색으로 표현한다. 또한 중심점을 나타내기 위해서
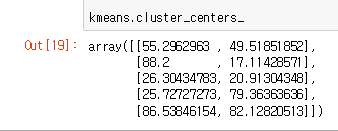
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s = 300, c = ‘yellow’, label = ‘Centroids’)
노란색 점으로 군집들의 중심점을 표시해준다. 해당 군집들의 중심을 보기 위해서 kmeans.cluster_centers_ 를 사용하면 중심 값들이 나온다.
plt.legend()
legend() 가 뭔지 정확히 알고싶은 사람들은 아래 글과 블로그 참고하십슈 ㅎㅎ
matplotlib로 그림을 열심히 그리고 나서, “이 색깔의 모양 저것은 무엇이고…” 하는 식으로 설명을 덧붙이면 매우 피곤해집니다. <br>이런 짓을 좀 덜 하려면 legend만 잘 넣어도 됩니다. plt.legend()만 넣어주면 되긴 합니다.<br> 물론, 이렇게 하려면 figure에 새로운 그림을 넣어줄 때마다(scatter, or plot, …) label을 함께 넘겨줍니다. <br>잘 넣어주면, 나중에 plt.legend()를 해주면 알아서 잘 출력해줘요.
[출처< https://frhyme.github.io/python-lib/matplotlib_legend/> ]
사실 이거 읽을 필요는 없구 그냥 아래 사진의
빨간동그라미 같은 저런걸 legend() 함수가 해줌 ! ! ! ! !
참고자료
https://bcho.tistory.com/1203 https://wikidocs.net/4694 https://kongdols-room.tistory.com/91 https://kongdols-room.tistory.com/92 https://rfriend.tistory.com/250