jupyter Notebook으로 Kmeans 연습하기 using Python
https://www.youtube.com/watch?v=9TR54u08IGU 강의를 참고하며 글을 쓴다.
k-means steps
- prepare Data
- decide how many clusters you need
- choose initial center of cluster(centroid)
- randomly select centroid
- manually assign centroid
- kmeans++
- assign data point to nearest clusters
- move centoid to the center of its cluster
- repeat step 4 and step 5 until there is no assigned cluster change
kmeans++
initial centroid 를 정하는 방법 중 하나로
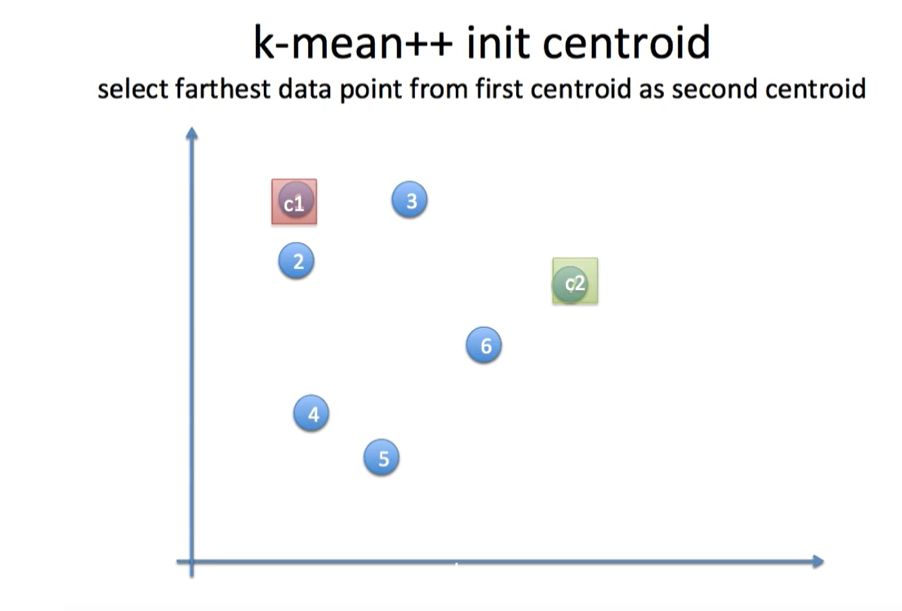
C1에서 가장 먼 곳에 c2를 배치한다.
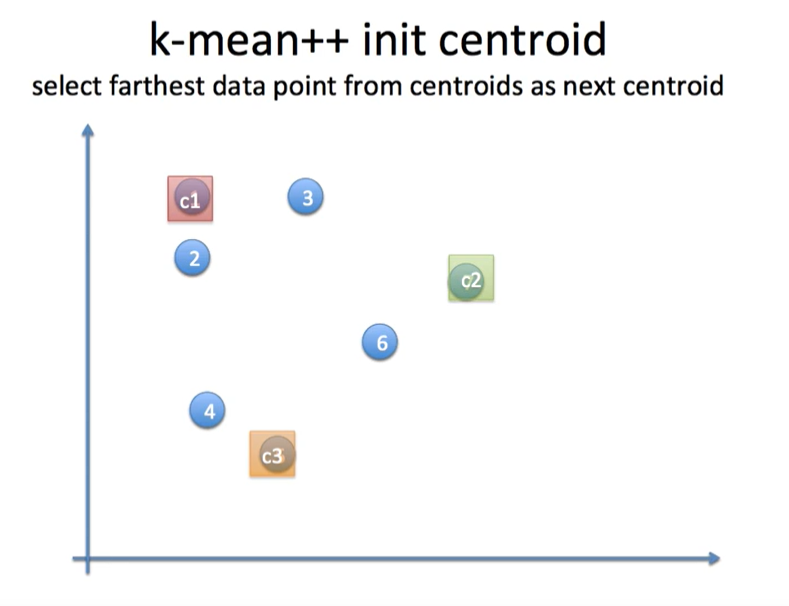
c1 과 c2에서 공통적으로 가장 먼 곳에 c3 도 배치
데이터셋 준비
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
df = pd.DataFrame(columns=[‘x’,’y’])
df.loc[0] = [3,1] df.loc[1] = [4,1] df.loc[2] = [3,2] df.loc[3] = [4,2] df.loc[4] = [10,5] df.loc[5] = [10,6] df.loc[6] = [11,5] df.loc[7] = [11,6] df.loc[8] = [15,1] df.loc[9] = [15,2] df.loc[10] = [16,1] df.loc[11] = [16,2]
12개의 데이터 프레임을 만들기
df.head(20)
만든 데이터를 차트 형식으로 확인할 수 있음
sns.lmplot(‘x’,’y’,data=df, fit_reg=False , scatter_kws={“s”:200 })
plt.title(‘kmeans plot’)
plt.xlabel(‘x’)
plt.ylabel(‘y’)
- sns.lmplot(‘x’,’y’,data=df, fit_reg=False , scatter_kws={“s”:200 }) seaborn 에 있는 lm 차트로 2D 차트를 생성한다는 의미
x,y 의 데이터를 위에서 미리 만들어 놨던 df 데이터 에서 가져오고 fit_reg 는 선을 그릴지 말지를 의미하는데 선이 필요 없기 때문에 False scatter_kws 는 그래프에서 나타낼 데이터 포인트 크기를 의미하는데 200으로 설정
- plt.title(‘kmeans plot’) plt.xlabel(‘x’) plt.ylabel(‘y’)
그래프 타이틀을 kmeans plot 으로 하고 각 x,y 축의 레이블을 x , y 로 둠
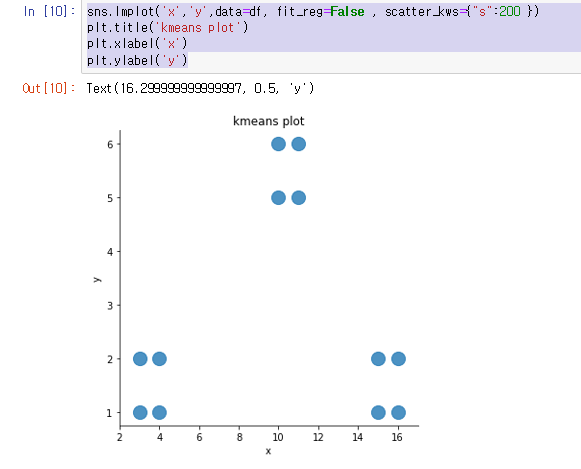
아직은 k-means clustering을 하기 전이기 때문에 모든 색상이 동일함
k-means clustering
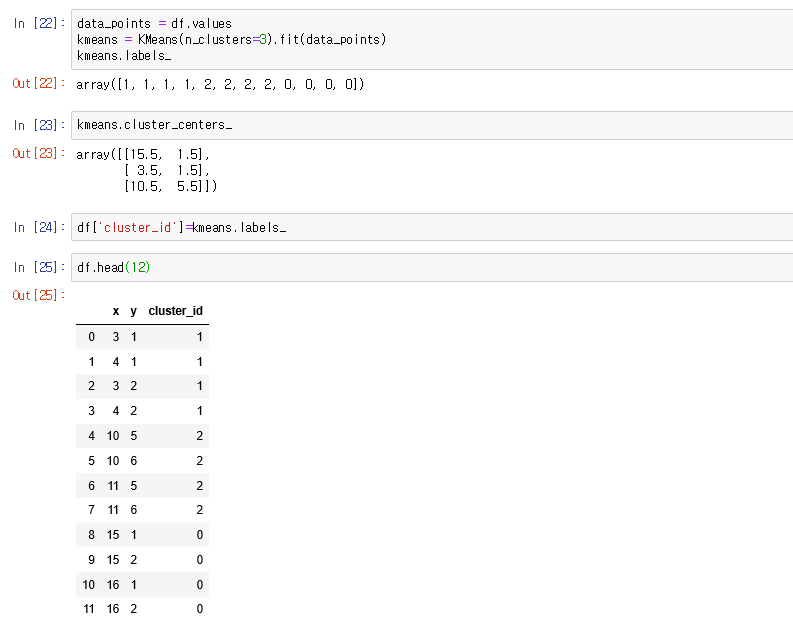
data_points = df.values
kmeans = KMeans(n_clusters=3).fit(data_points)
kmeans.labels_
df 데이터를 valuse 라는 함수를 사용하여 numpy 형태의 array로 변경시킴 kmenas 변수에 3개의 클러스터가 필요하다는 의미로 n_clusters = 3 이라고 기입을 한다. 여기서 이니셜 centroid 를 따로 지정하지 않으면 kmeans ++ 로 지정을 함
kmeans.labels 에는 각각에 데이터에 대한 클러스터 넘버가 적힘
kmeans.cluster_centers_
각각의 클러스터에 잇는 cenroids 의 지점 x,y 값
df[‘cluster_id’]=kmeans.labels_
df 데이터를 cluster_id 로 하고 이 kmeans 에 label 을 cluster_id 로 붙혀줌
df.head(12)
sns.lmplot(‘x’,’y’,data=df, fit_reg=False , scatter_kws={“s”:150 },hue=”cluster_id”)
plt.title(‘after kmean clustering’)
- scatter_kws : marker size hue : color
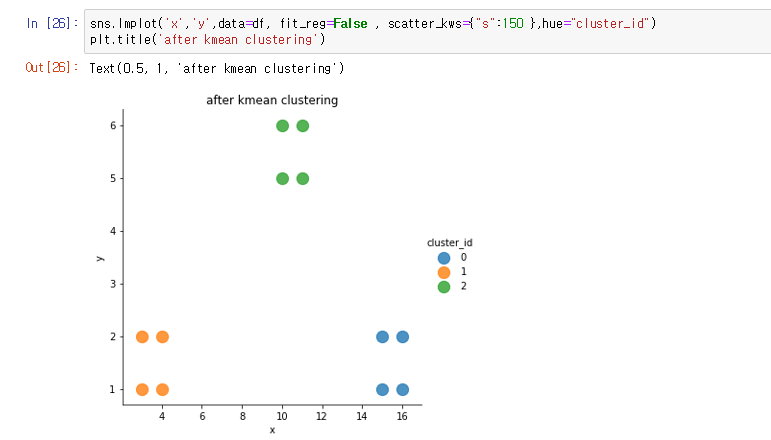
cluster_id 로 군집화 하여 색을 다르게 한 뒤 시각화 한 걸 확인할 수 있다.