[Ubuntu]Apache Hadoop 설치하기
Hadoop 의 구축 방법
- 단독 작업 모드 (Stand-Alone Operation)
- 가상 분산 모드 (Pseudo-Distributed Operation)
- 완전 분산 모드 (Fully-Distributed Operation)
●독립모드(Standalone mode)
데몬 프로세스가 동작하지 않고, 모든것이 단독 JVM 내에서 동작. 개발하는 동안 맵리듀스 프로그램을 동작시키기에 적합한데, 테스트하고 디버그가 쉽기 때문이다.
●의사분산모드/ 가상분산모드(Pseudo-distributed mode)
하둡 데몬 프로세스가 로컬컴퓨터에서 동작하므로 작은 규모의 클러스터를 시뮬레이트 할 수 있다.
●완전분산모드(Fully distributed mode)
하둡 데몬프로세스는 다수 컴퓨터로 구성된 그룹에서 동작한다.
출처: https://jy86.tistory.com/entry/ㅇ [JY World!!]
나는 가상 분산모드 할거임
가상분산모드를 하기 위해서는 가상머신 먼저 다운받아야 한다. https://webnautes.tistory.com/448 https://wnw1005.tistory.com/186 아래 블로그가 더 최신 버전 다운받는 방법을 보여주는 블로그
참고로 확장팩은 굳이 필요없으니 안다운받아도됨
진짜 개오래걸렸다 ^^ 후 ,, 가상머신은 다운받을 때마다 적응안됨 + 시간 오래걸림 오전시간 다날리고 2시간 더걸림
~ 순서 ~
- 하둡 설치하기
- 하둡 서버 구축
- 하둡 스파크 연동
하둡(Hadoop) 설치하기
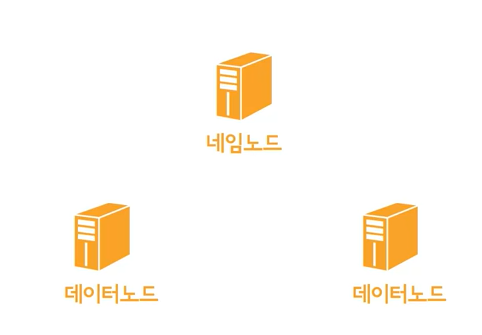
영상에서는 위의 사진과 같은 3대의 가상머신을 만들었다. 네임노드 : 파일을 쪼개고 쪼개진 파일이 어떤 데이터 노드에 저장되어져 있는지 기억하는 컴퓨터 데이터 노드 : 실제 사용자가 업로드한 데이터를 쪼개진 형태로 보관하고 있는 컴퓨터
파일의 이름이나 경로는 네임노드에 저장되고 , 실제 데이터는 데이터 노드에 분산되어 저장되어져 있음
하둡은 자바로 개발이 되었기 때문에 java가 가장 접근성이 좋지만 php, python 으로도 제어할 수 있다.
하둡은 큰 데이터를 처리하기 위해 만들어 졌기 때문에 작은파일도 병렬처리로 처리를 하기 때문에 시간이 오래걸린다.
나는 가상머신 2개를 이용해서 분산 컴퓨팅 환경을 구축하려고 한다. 컴퓨터 사양 문제로 2개만 사용할 예정 ( master-slave )
아 그리고 가상머신은 virtual box 를 사용할 것이다.
서버 환경 구성하기
ssh 다운로드가 안받아져 있거나 ssh 대해 모르는 사람들(나)이 참고했으면 하는 블로그 글 http://magic.wickedmiso.com/101
sudo apt-get update
sudo apt-get upgrade
sudo add-apt-repository ppa:webupd8team/java
엔터키
sudo apt-get update
sudo apt-get install openjdk-8-jdk
참고로 java8-installer 어쩌고 이거 이제 안돼요 ㅠ ㅠ 대신 openjdk 로 하심 댑니다 !! .. 훨 쉬운듯 ㅎㅎ
sudo apt-get upgrade
java -version
확인
sudo addgroup hadoop
sudo adduser –ingroup hadoop slave
비밀번호 입력한 뒤 엔터 계속 친 뒤 Y 를 입력해 등록
sudo gedit /etc/sudoers
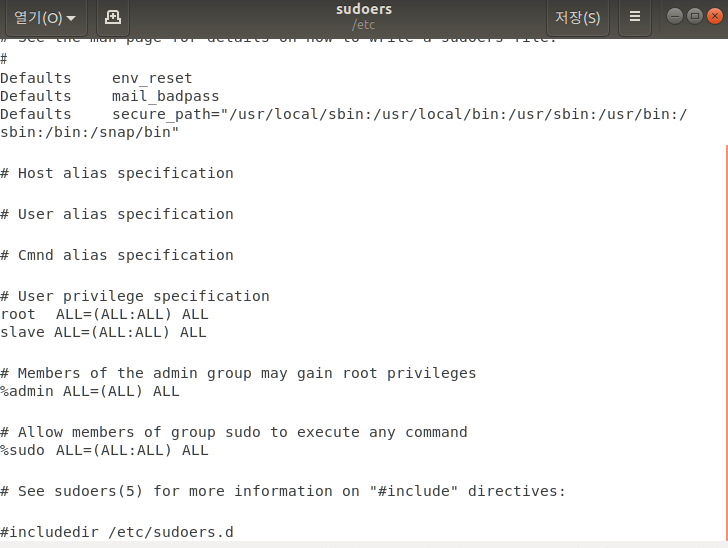
#User privilege specification 항목에 root 부분 아래에 위에 그룹에 추가한 user 이름 추가
apt -get install openssh-server
ssh 다운로드 후
sudo su slave
sudo su user이름
cd
ssh-keygen -t rsa -P “”
엔터
cat $HOME/.ssh/id_rsa.pub » $HOME/.ssh/authorized_keys
sudo reboot
ubuntu 브라우저를 통해
http://mirror.navercorp.com/apache/haddop/common 에 접속해서 파일 다운로드
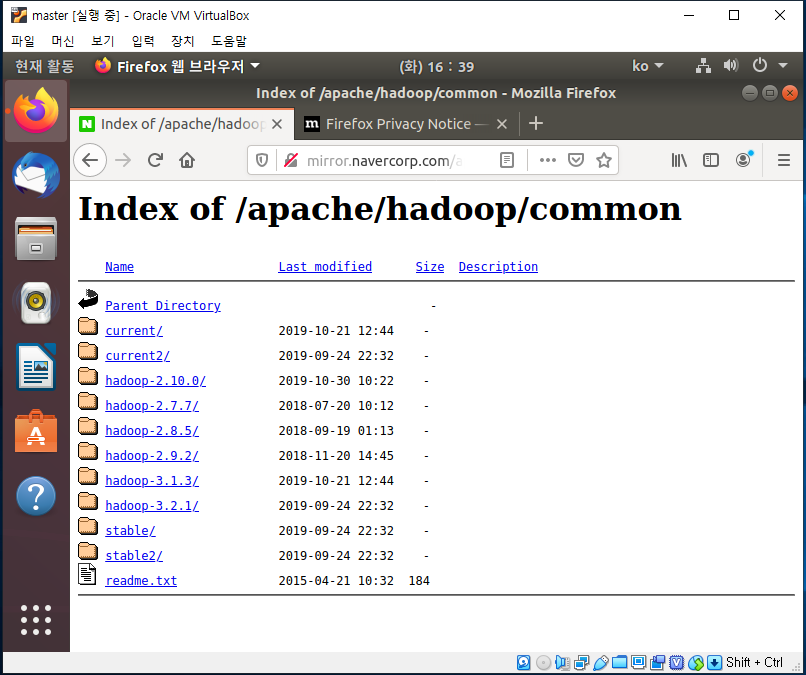
여기서 hadoop-2.10.0 버전 다운받았음
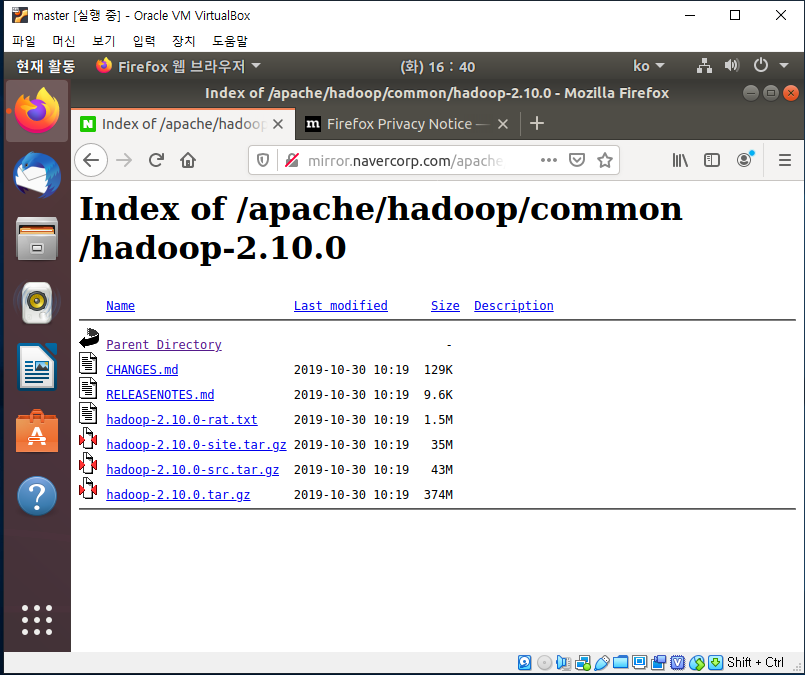
맨 마지막 파일 hadoop-2.10.0.tar.gz 를 다운
파일 저장 선택 후 압축 풀고 바탕화면에 복사한 뒤 압축 풀기
터미널로 이동하여서
sudo su slave
cd
sudo mv ‘/home/master/바탕화면/hadoop-2.10.0’ /home/master/hadoop
바탕화면에 있는 파일을 내가 원하는 경로 ( hadoop 이라는 폴더를 만들었음 ) 로 이동시킴
sudo chown slave:hadoop -R /home/master/hadoop
sudo mkdir -p /home/master/hadoop_tmp/hdfs/namenode
sudo mkdir -p /home/master/hadoop_tmp/hdfs/datanode
sudo chown slave:hadoop -R /home/master/hadoop_tmp/
sudo gedit .bashrc
텍스트 편집기가 뜨면 맨 마지막 부분에
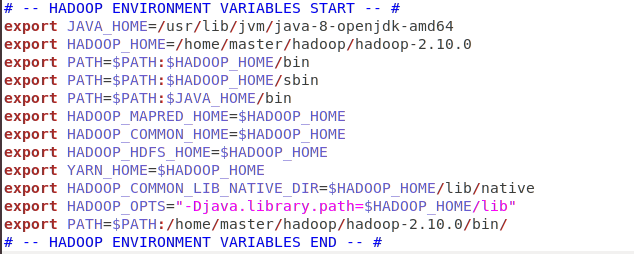
이 문구를 추가 한 뒤 저장 (경로 잘 보세요 ! 각자 만든 경로대로 적어줘야 함 !!)
cd /home/master/hadoop/hadoop-2.10.0/etc/hadoop
sudo gedit hadoop-env.sh
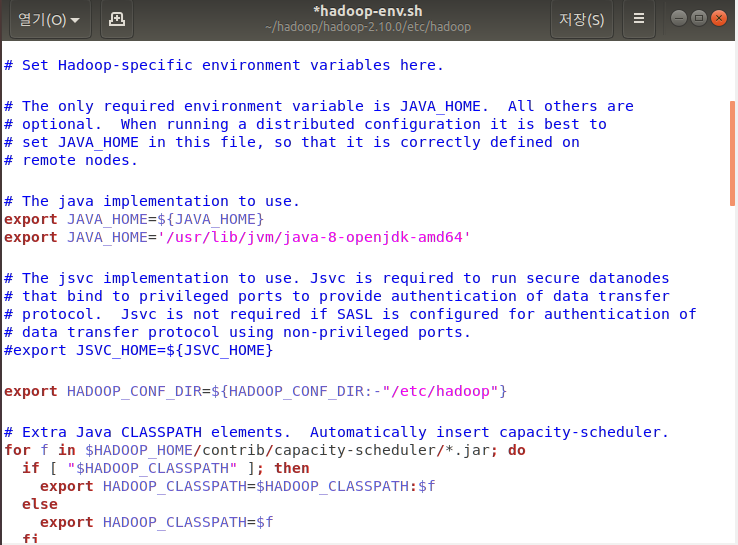
#the java implementation to use 부분에 export JAVA_HOME 밑에 새로운 JAVA_HOME 경로 추가 ! (위에 환경변수 설정한 JAVA_HOME 경로랑 같아야해용)
sudo gedit core-site.xml
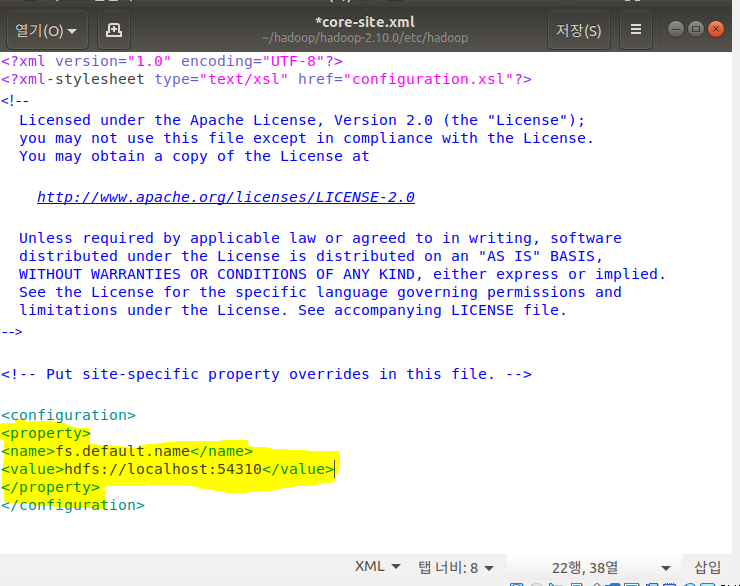
‘configuration’ 태그 안에 형광펜 친 부분 추가
sudo gedit hdfs-site.xml
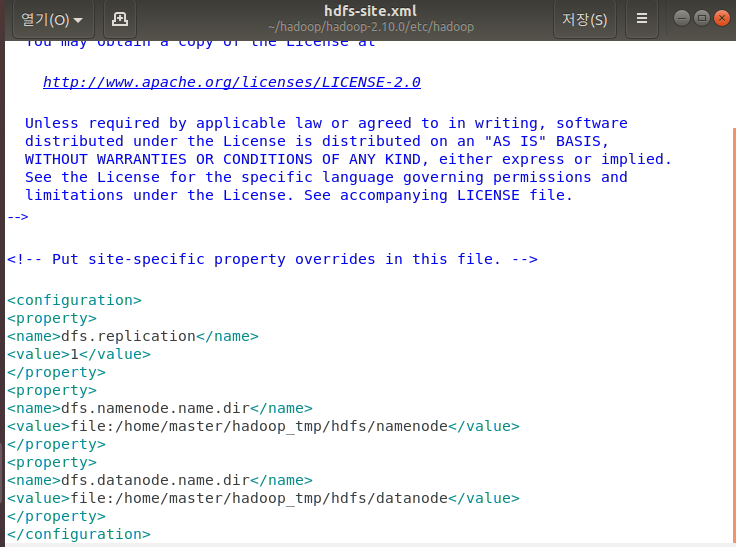
‘configuration’ 태그 안 부분 다 추가 ! datanode 랑 namenode 는 아까전에 생성해놓은 그 경로로 해야해용 !!
sudo gedit yarn-site.xml
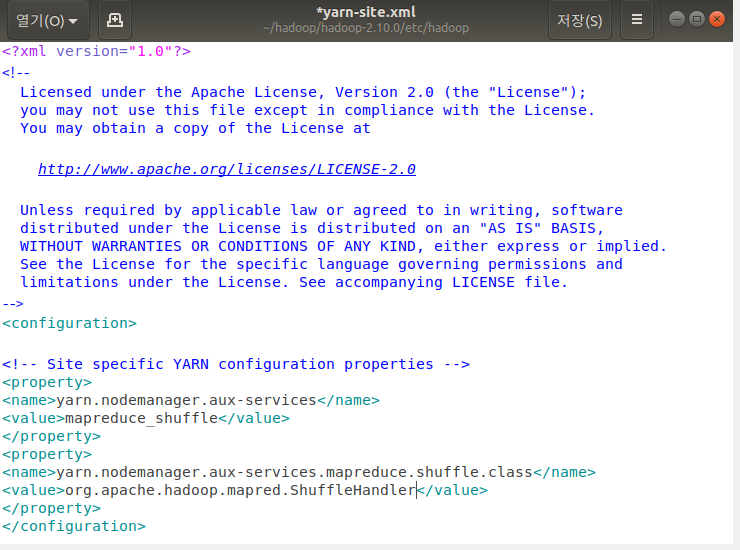
‘configuration’ 태그 안에 부분 추가 후 저장
cp /home/master/hadoop/hadoop-2.10.0/etc/hadoop/mapred-site.xml.template /home/master/hadoop/hadoop-2.10.0/etc/hadoop/mapred-site.xml
sudo gedit mapred-site.xml
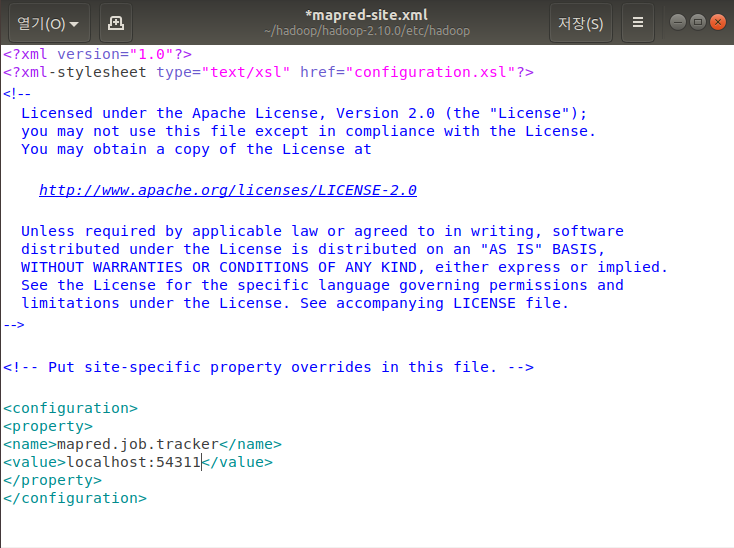
가장 밑에 다음과 같은 문구 추가한 후 저장
cd
source ~/.bashrc
cd /home/master/hadoop_tmp/hdfs

(경로 확인 잘하세용)
hadoop namenode -format
???????!!!!!!!!!!!!!!!!!!!! hadoop 없는 명령어다 ㅇㅈㄹ 하는데 아주 화남 ㅎㅎ
가상머신이랑 맞짱뜨고 하둡이랑 2차 싸우다가 화딱지 날 것 같다 .. . . . . ..
와 ㅎㅎ 해결함 ,, 오늘의 교훈 ,, 터미널을 여러개 열어놓지 맙시다..^^그리고 경로 !!! 잘 확인해야함 !!!!!!!!!! 터미널 여러개 열어놓고 했다가 다른 경로의 같은 이름의 파일 (source ~/.bashrc) 을 잘못 수정한듯 했음 .. 다시 시도해보니 나는 분명 파일을 수정했는데 깨-끗해서 당황해찌만 바로 다시 적고 그 이후 과정들을 다시 실행하니 되었다 ..
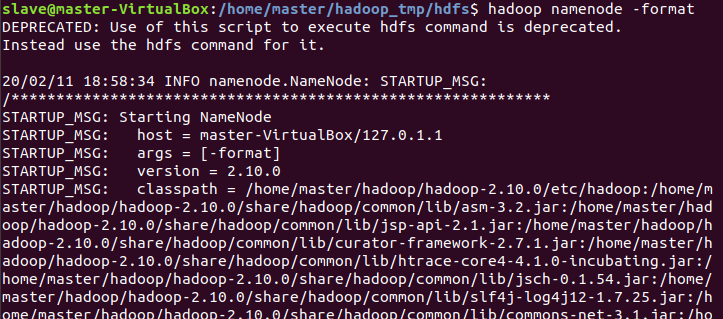
해결 완료 ㅎㅎ 이렇게 뜸 !! 성공하면 ! 엄청 길다 뭐 뜨는 문구들이
cd /home/master/hadoop/hadoop-2.10.0
start-dfs.sh
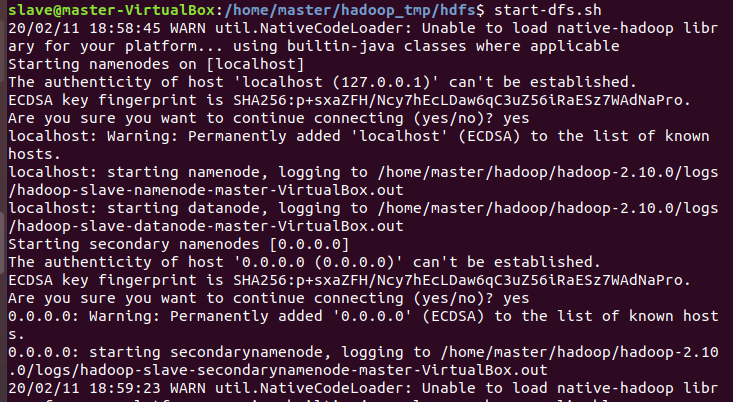
yes 입력 후
start-yarm.sh
jps
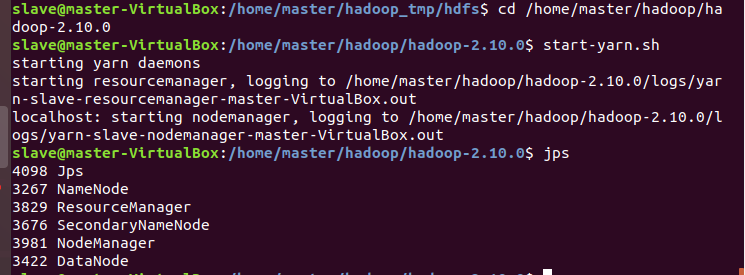
jps 했을 때 이렇게 뜨면 성공 ~!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
드디어 길고도 험난했던 hadoop 다운이 끝났네요 ^_ ^ … 진짜 ….. 다음에는 spark 설치와 … spark hadoop 연동 하겠읍니다 …………
참고 https://daeson.tistory.com/277?category=679387 https://bisn.tistory.com/9 https://riothaid.tistory.com/178